Parents increasingly rely on data-driven measures of school quality to choose schools, while districts use the same information to guide policy. School quality information often comes in the form of “school report cards” like New York City’s School Quality Snapshot and “school finder” websites, like GreatSchools.org. These school ratings are highly consequential, influencing family enrollment decisions and home prices around the country. State and district restructuring decisions, such as school closures or mergers, also turn on these measures. In short, school performance measures matter.
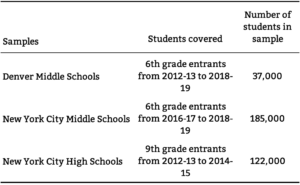
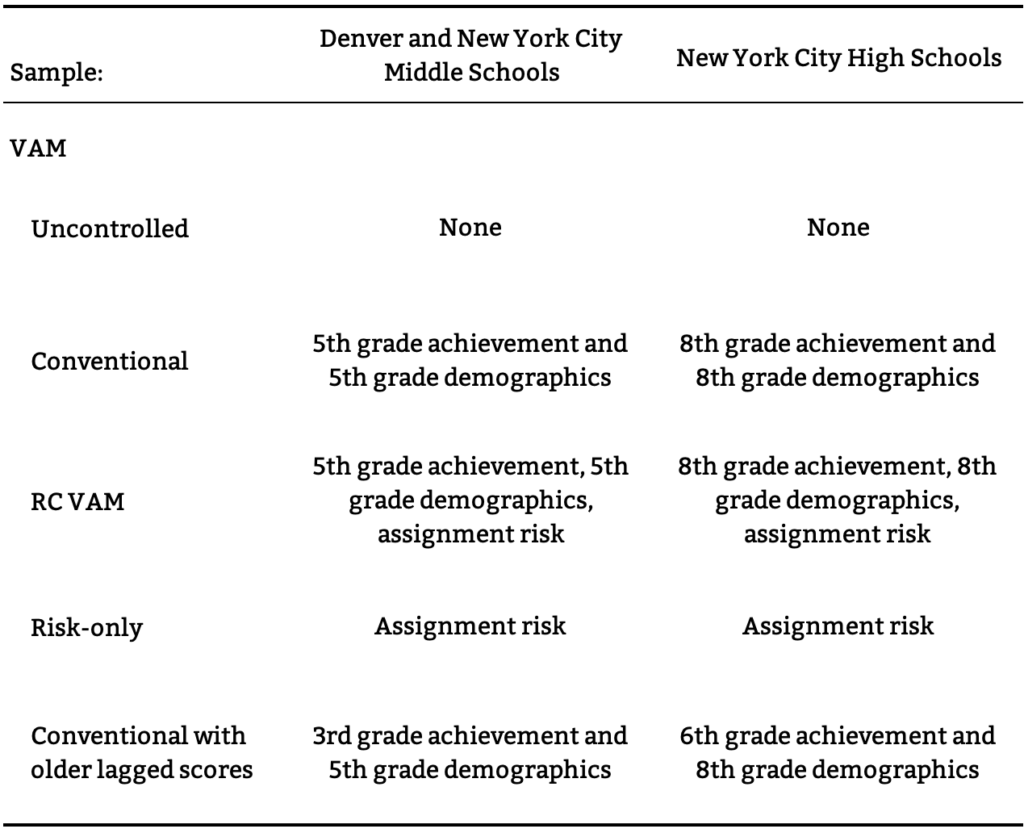
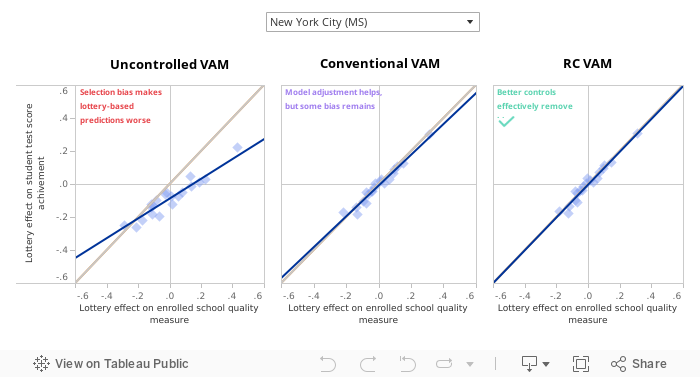
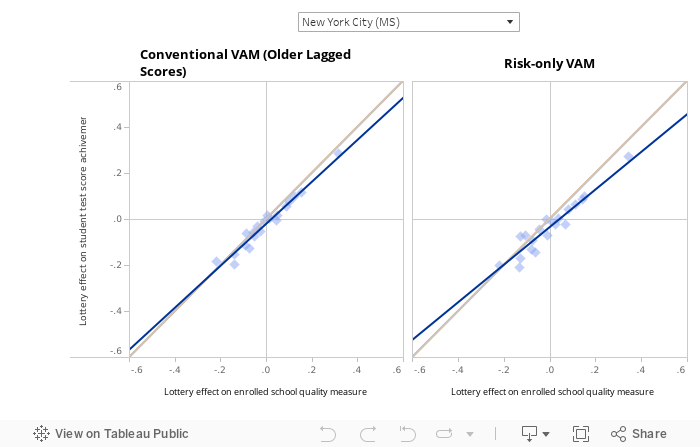
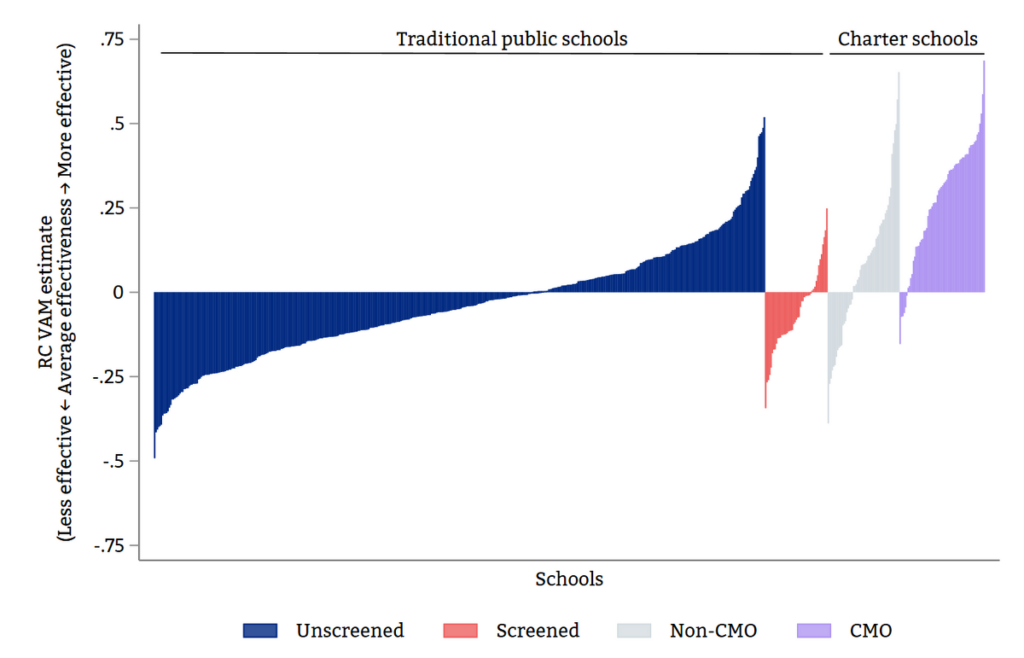
Our study examines the predictive validity of alternative school performance measures to show how they can be improved in districts that use centralized assignment to match students to schools. Using data from New York City and Denver, we show that a new approach that harnesses student data from centralized assignment, which we call a risk controlled value-added model (RC VAM), improves upon conventional methods. We also study a range of other value-added models. In practice, analysts may not have the data required to compute RC VAM and not all districts assign seats centrally. Our study sheds light on approaches that might best serve as performance measures in the absence of ideal data.
The validity of school ratings is important to both policymakers and parents, who rely on them for consequential decisions. Inaccurate measures of school quality can unfairly reward or punish schools erroneously deemed to be more or less effective. For organizations that engage in the provision of quality measures, the methods developed in our study offer a new tool that can provide fairer assessments of school effectiveness.
How do you measure school quality?
One of the most common school performance measures compares average standardized test scores across schools. While this seems natural, such simple comparisons can be misleading. The difference between “high-achieving” and “low-achieving” schools may reflect differences in students’ background or preparation as much or more than the causal impact of a school on student learning. In other words, schools may appear more or less effective because of the types of students they enroll, rather than the quality of their instruction. Researchers refer to this as the problem of selection bias.
The figures below illustrate selection bias. Imagine a small district with only two schools, which we label A and B. Students at school A are high-achievers and score an average of 92 on a standardized math test. Students at school B are lower-achieving, with an average score of only 80. Comparing school A and B, we might conclude that school A is more effective than school B because its students have better outcomes.
Achievement Levels
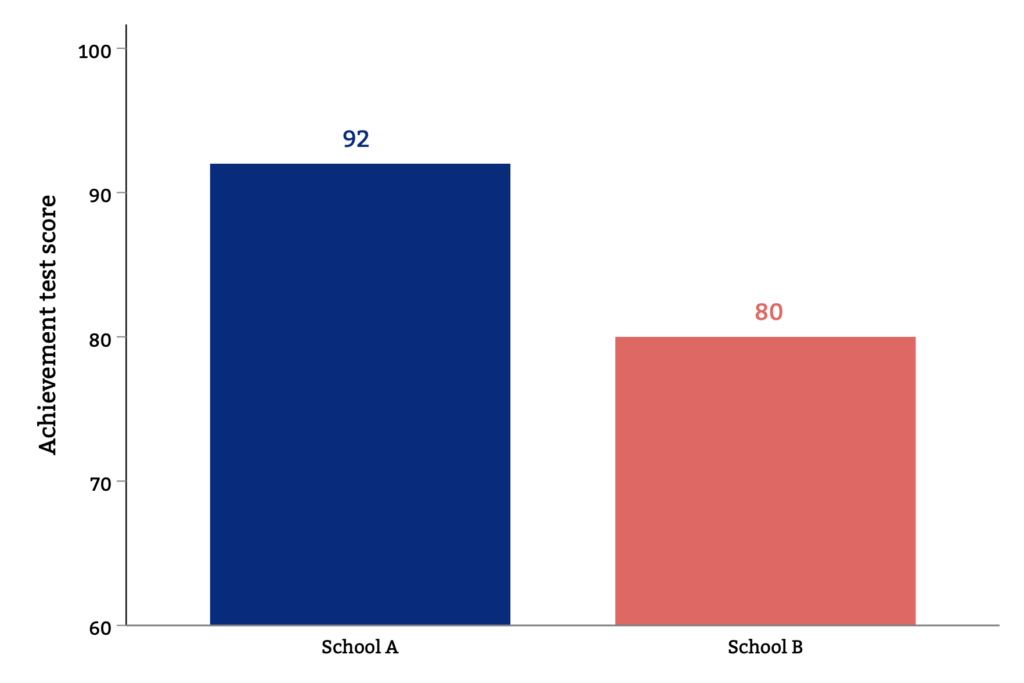
While easy to calculate, simple differences in achievement levels do not necessarily reveal the extent to which schools increase student learning. In practice, high achievement at A might reflect the fact that this school is located in a higher-income neighborhood. Higher-income students tend to have higher test scores, regardless of school quality.
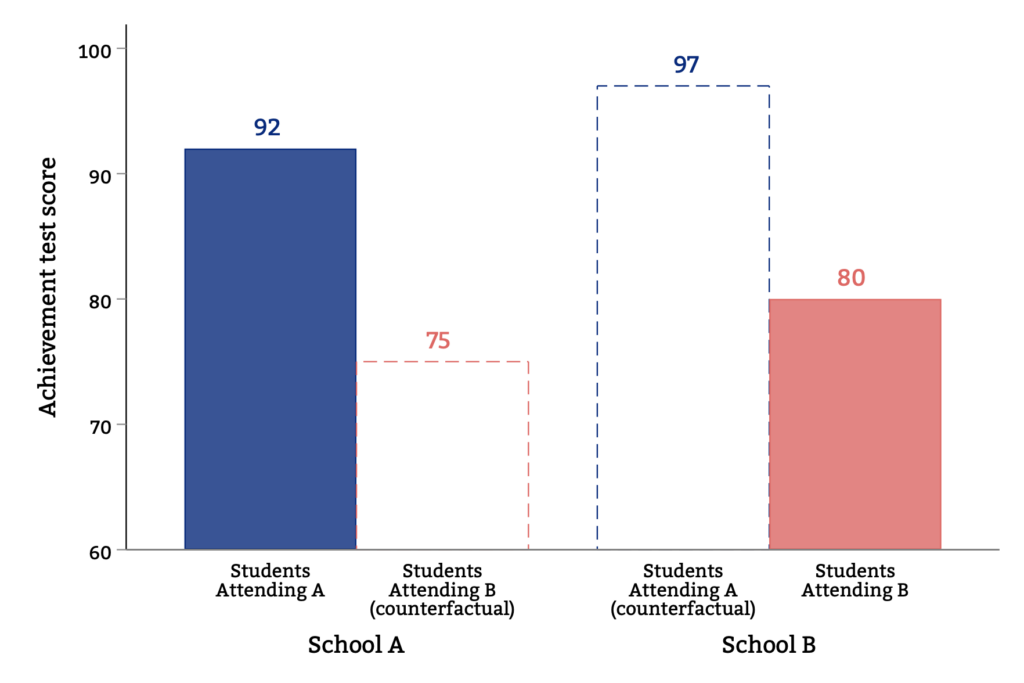
The causal effect of school attendance contrasts achievement for the same students had they attended a different school. Outcomes that we cannot observe for a given student are said to be the counterfactual.
We plot examples of such counterfactuals in the figure below. The figure shows how students attending A would have learned more if they had instead attended B (the dashed blue bar), while the students at school B would have learned less if they had instead attended A (the dashed pink bar). In this example, school B is higher quality than school A— it boosts test scores relative to the counterfactual, whereas school A lowers test scores. This is in spite of the fact that students at A have higher test scores.
Observed and Counterfactual Achievement
We learn about these counterfactual outcomes with the help of more sophisticated analyses designed to capture causal impacts. These tools include value-added models (VAMs) and student growth models. For example, a value-added model might control for students’ achievement in elementary school when measuring middle school quality. Growth models aim to eliminate selection bias by controlling for, or holding constant, differences in student ability. For example, a growth model might control for students’ demographics and baseline achievement to proxy for ability. The hope is that such adjustment moves us closer to a counterfactual-based analysis of school quality, by removing observable differences in student characteristics that might otherwise bias simple comparisons of achievement levels. In practice, however, these adjustments for student characteristics may or may not be adequate. Our study examines the degree to which different modeling approaches indeed capture causal effects.